Group Chat vs. Live Stream Messaging: A Comparison
Introduction
Real-time messaging is everywhere, but “real-time messaging” actually covers two systems with very different engineering constraints: group chat and live-stream messaging. Both connect people instantly, but the contexts — a 1,000-person work group versus a million-viewer broadcast — pull the design in opposite directions. This article compares the two on architecture, performance, delivery guarantees, and security, and explains why each makes the trade-offs it does.
Definitions and Use Cases
Group Chat
Group chats are persistent online spaces where multiple people communicate in real time — team collaboration, social circles, interest communities. Messages are stored, and participants can scroll back through history at any time. Slack, Discord, and WhatsApp are familiar examples.
Use cases: Team collaboration: discuss projects, share files, make decisions together. Social groups: friends and family stay in touch and plan events. Communities: people with shared interests exchange ideas and offer support.
Live-Stream Messaging
Live-stream messages are real-time comments and interactions during a live broadcast. They appear on screen instantly, letting the audience react to the streamer and to each other. Twitch, YouTube Live, and Facebook Live all provide this.
Use cases: Audience interaction: viewers ask questions and react in real time. Events and webinars: attendees join polls and Q&A. Gaming streams: streamers get live feedback and build community.
The rest of this article goes deeper into how each is built, and where the two diverge.
A First Comparison
| Dimension | Group Chat | Live-Stream Messaging |
|---|---|---|
| Participants | ~1K | ~1M |
| Relationship chain | present | absent |
| Membership churn | low | high |
| Offline messages | prioritized | deprioritized |
| Session duration | long | short |
| Security | end-to-end encryption (optional) | none |
From this table, live-stream messaging has two hard problems. (The magnitudes below come from the production figures reported in the Baidu and WeChat systems cited in the References.)
- User maintenance
- Tens of thousands of users join and leave a room every second (peaking near 20K entries/sec and 20K exits/sec).
- A single room can have millions of users online at once.
- Cumulative entries into a room reach tens of millions.
- Message delivery
- With millions online, the inbound and outbound message volume is enormous.
- Some messages — gifts, co-streaming requests — must be delivered reliably even though most can be lossy.
The first problem is comparatively easy to solve, so the discussion below focuses on the second.
Architecture and Infrastructure
Group Chat
Message Diffusion
Group chats use one of two diffusion models — read diffusion or write diffusion — and the choice is the defining architectural decision:
- Read diffusion: the message is stored once, in the group’s shared mailbox, and every member pulls from there. Cheap to write (one copy), more expensive to read (every reader does the fan-out at read time).
- Write diffusion: when a message is sent, a copy is dispatched into each member’s personal mailbox. Cheap to read (your inbox is already assembled), more expensive to write (fan-out on every send).
That said, even under read diffusion each member still carries per-user state — their own fetch_msgid, ack_msgid, read_msgid, begin_msgid, and so on. That bookkeeping is unavoidable in either model, but it’s cheap: a handful of cursors per member that point into the single shared store, not copies of the message body. The expensive choice is whether you also dispatch a copy of each message into every member’s mailbox — that’s write diffusion. To make the fan-out cost concrete, the rest of this section works through the write-diffusion model directly.
A group message fans out twice: 1 group → m users, then 1 user → n devices. Here m is the group size (typically ≤ 1K) and n is the devices per user (typically ≤ 5).
The amplification is the whole problem. If 1,000 groups each send one message at once, the fan-out is on the order of 1,000 groups × 1K members × 5 devices ≈ 5 million dispatches per round. As traffic grows, this splitting step is what dominates resource consumption, and it’s the pressure point huge groups have to design around. There’s no single industry answer: some systems keep write diffusion and absorb the multiplier by bounding group size, sharding, and merging the fan-out (Enterprise WeChat dispatches into per-member streams even for ten-thousand-member groups); others lean toward read diffusion (fan-out on read), trading cheaper writes for heavier reads. The rough heuristic is to write-diffuse small groups for fast reads and consider read diffusion for huge ones to cap write amplification — but note this only moves where the cost lands. Even read diffusion still carries the per-user cursors from above, so per-user state has to be dispatched either way; the model choice decides whether you pay for it on write or on read, not whether you pay at all.
Storage and Retrieval
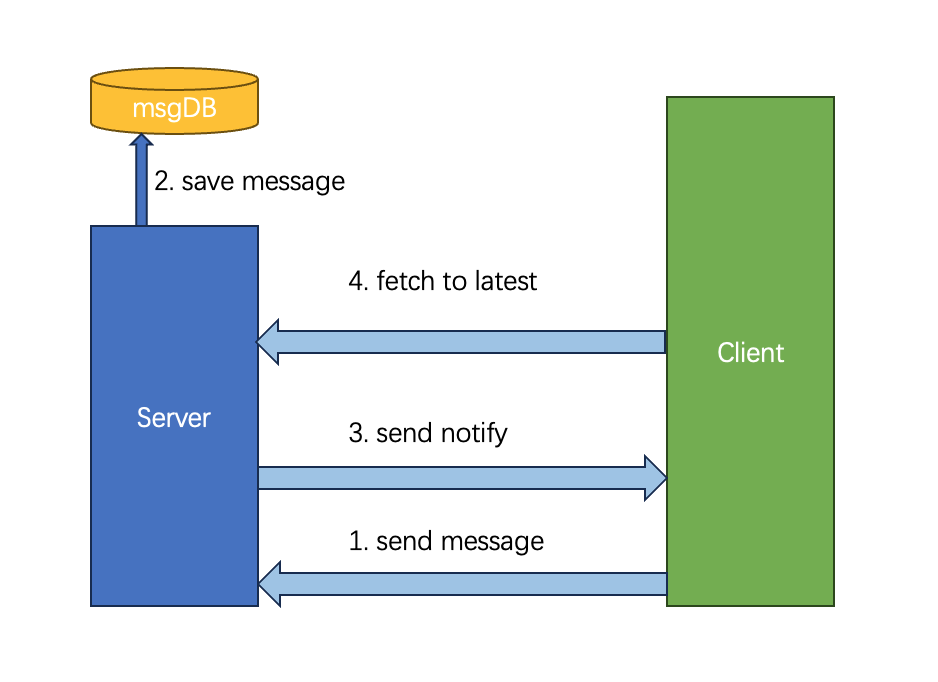
Group chat combines push and pull to keep messages from being lost. If the server pushed directly and the notification were dropped, the message would be lost with it. So the standard approach is: on receiving a message, store it first, then notify the client that something new arrived; the client then pulls the new messages. If a notification is lost, the next pull still recovers the message, because the durable store — not the notification — is the source of truth.
This is what makes the gap detectable: each user’s messages carry a contiguous per-user sequence number — the high-water mark behind the fetch_msgid/read_msgid cursors above — so when the client holds up to 100 and the server’s notification (or the pull response) says 105, the missing 101–105 are unambiguous and the client pulls them. Reliability therefore comes from continuity of the sequence, not from any single delivery succeeding. (The trick depends on the sequence being dense: a merely monotonic but sparse ID, where 100 and 105 might be adjacent, could not signal a gap.)
Security and Privacy
Compared with C2C, where end-to-end encryption is relatively straightforward, E2E encryption in group chat is much costlier (key distribution and rotation across a changing membership). Workable designs exist — iMessage and Signal among them — but the topic is involved and out of scope here.
Live-Stream Messaging
Typical Architecture
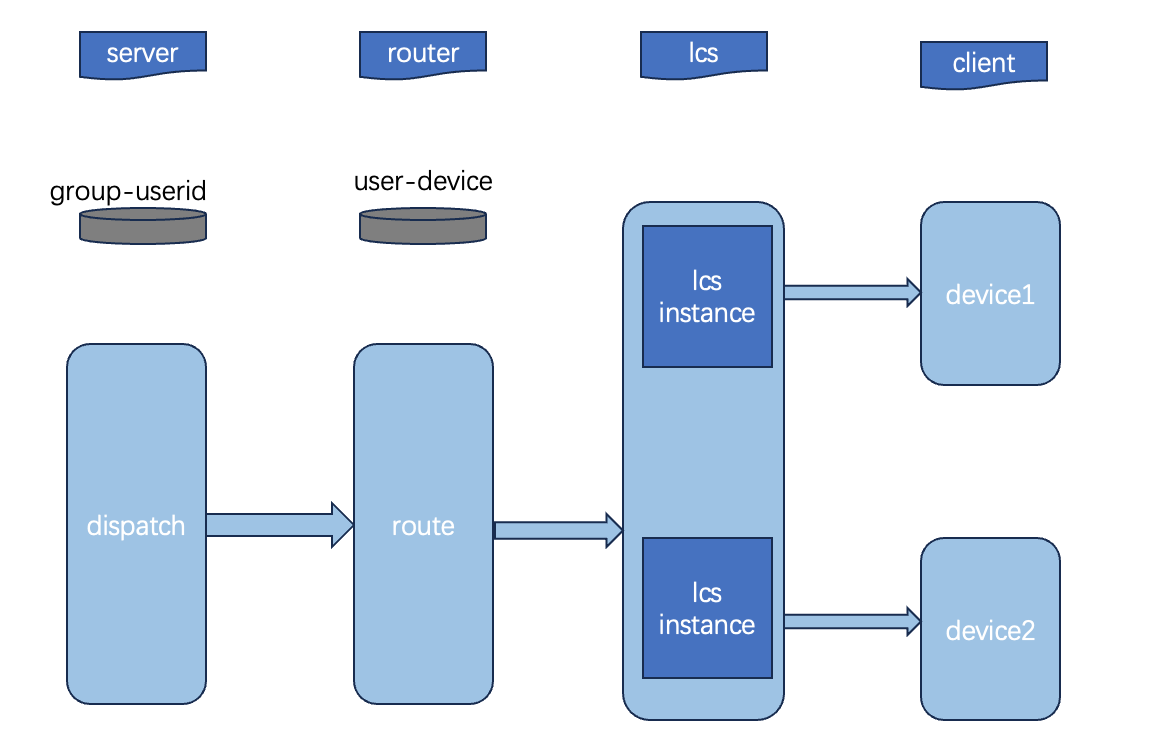
Live-stream messaging amplifies in two stages, 1 → m → n:
- m is the number of LCS (Long Connection Service) instances holding viewers of the room.
- n is the number of connections joined to a given multicast on a single instance.
m can reach roughly a hundred instances, and because n lives entirely in memory a single instance comfortably holds on the order of 250,000 connections. So ~100 instances × ~100,000 active connections each is enough to carry 10 million simultaneous connections in one room — and since each instance can hold ~250,000, that figure is a peak the layout absorbs with headroom, not its ceiling. The two stages are decoupled by design: the publisher writes a single message, the route layer dispatches it to the handful of instances that hold the room (m), and only then does each instance fan it out across its own connections (n). The wide n multiplier never crosses a service boundary — it stays inside each instance’s process — which is exactly what keeps 1 → m → n affordable.
The contrast with group chat is the point: group chat fans out to ~1K durable mailboxes; a live room fans out to millions of in-memory connections. Store-and-notify per viewer is impractical at that width, so the architecture shifts from durability to throughput.
Route Layer
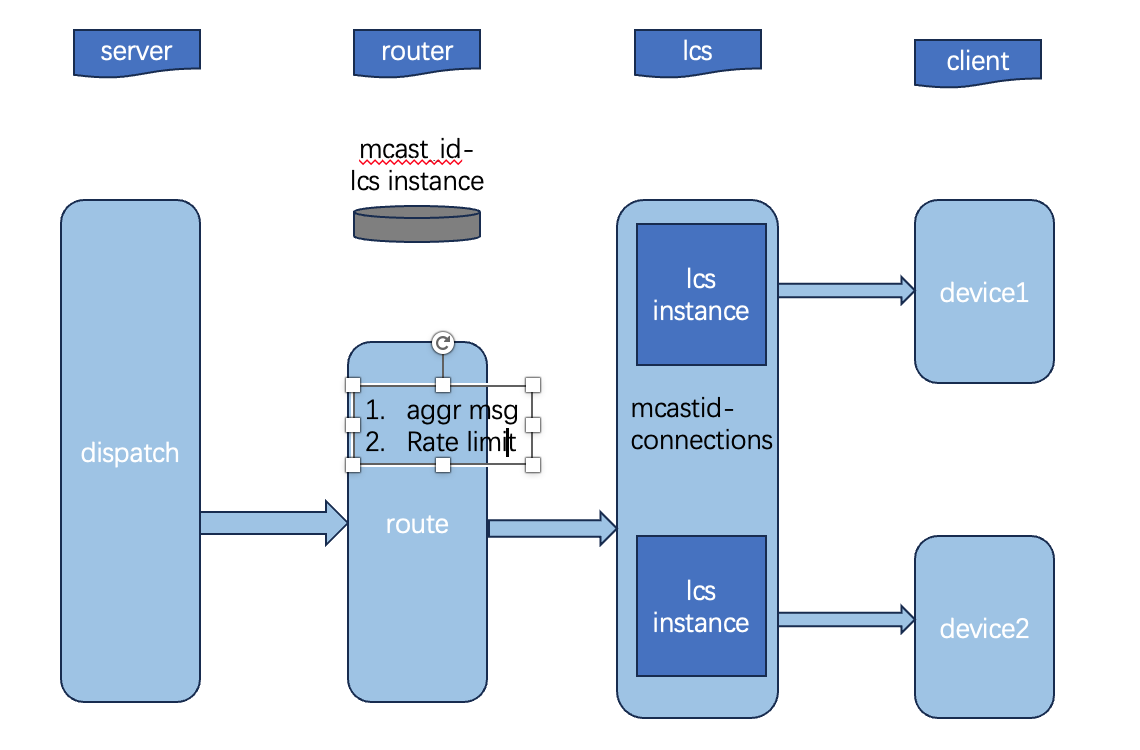
The route layer’s main jobs:
- Resolve which LCS instances hold connections in the room, by
mcastid. - Aggregate messages so each one isn’t notified individually.
- Apply rate limiting — if downstream capacity is exceeded, shed here.
- Prioritize messages — shedding and prioritization are the same mechanism from two sides: under overload the route layer drops from the low-priority chatter tail first, so high-priority and gift traffic stay intact.
LCS Layer
The LCS layer’s main jobs:
- Maintain the
roomID → connectionsmap. - Compress messages to cut bandwidth substantially.
- Deliver messages to clients.
These two maps are populated on join: when a viewer connects, the LCS instance adds the connection to its local roomID → connections map and registers the room with the route layer, which maintains the inverse roomID → {instances} index. Under churn this many memberships per second, both indexes are only eventually consistent — a viewer who just left may still catch a stray message or two — but that is acceptable precisely because the chatter channel is already lossy by design.
Aggregation at the route layer and compression at the LCS layer are the two throughput levers: one batches away per-message overhead, the other shrinks the bytes that overhead is spent on. Together they are what keeps fan-out to millions of in-memory connections affordable — rate limiting and prioritization decide what to drop or order, but these two decide how cheap each surviving push is.
Push vs. Pull
For group chat, messages must not be lost, so we use notify + pull. For live-stream chat the priority inverts: we can tolerate occasionally dropping a comment in exchange for timeliness, so we typically use push mode — sending messages straight to the client. Dropping the rare comment under load is acceptable; adding a second of latency to a live broadcast is not.
Gift Messages
Push mode is fine for ordinary chat, but it’s lossy: a disconnect can drop whatever was in flight. Some messages can’t tolerate that — gifts especially, which matter to the streamer and to revenue, along with things like co-streaming requests.
So these get special handling. They’re given higher priority in the push path, and, because priority alone doesn’t survive a disconnect, they also ride a separate, reliable data stream using notify + pull — the same store-then-notify-then-pull mechanism as group chat. This is affordable for exactly the reason it wasn’t for chatter: gifts are orders of magnitude rarer, so the durable channel only carries the gift rate, not the comment firehose — per-user cursors and store-then-pull, impossibly wide for ordinary comments, are perfectly tractable for the few messages that must survive a disconnect. The effect is a deliberate split: one lossy, low-latency channel for the high-volume chatter, and one durable channel for the handful of messages that must arrive.
Conclusion
Group chat and live-stream messaging look similar from the outside and are built very differently underneath, because their constraints differ. Group chat optimizes for durability: bounded membership, a relationship chain, message history, optional end-to-end encryption, and a store-then-notify-then-pull path that guarantees no message is lost. Live-stream messaging optimizes for immediacy at scale: unbounded, churning membership and a push-based path that trades occasional loss for low latency — with a separate reliable channel bolted on only for the messages that truly can’t be dropped.
The deeper pattern is that both are managing the same fan-out problem from opposite ends. Group chat fans out narrowly to durable mailboxes and pays for reliability; live-stream fans out massively to in-memory connections and pays for it with aggregation, compression, and selective reliability. Knowing which end of that spectrum you’re on tells you which guarantees to spend your engineering budget defending.