Troubleshooting a UDP Packet Loss Issue on Linux
Introduction
A few years ago, while working on a QUIC-based project, I ran into a peculiar case of UDP packet loss on Linux. It took me several days to pin down the root cause, so I want to document the investigation here — both as a record for myself and as a worked example of how to reason about packet loss systematically rather than by guesswork.
Terminology
- QUIC: A UDP-based, multiplexed, and secure transport (RFC 9000).
- Connection: A QUIC connection — shared state between a client and a server.
- Connection ID: The identifier of a QUIC connection.
- Connection Migration: Because a connection is identified by its Connection ID rather than by the 4-tuple, it can survive changes to the endpoint’s IP address and port — for example, when a client moves to a new network.
- QUIC client: My QUIC client.
- BGW: My company’s layer-4 gateway — a proxy that is transparent to the user.
- Proxy server: A proxy that forwards packets in both directions.
- QUIC server: My QUIC server, which handles QUIC connections.
- quic-go: A QUIC implementation in pure Go.
Background
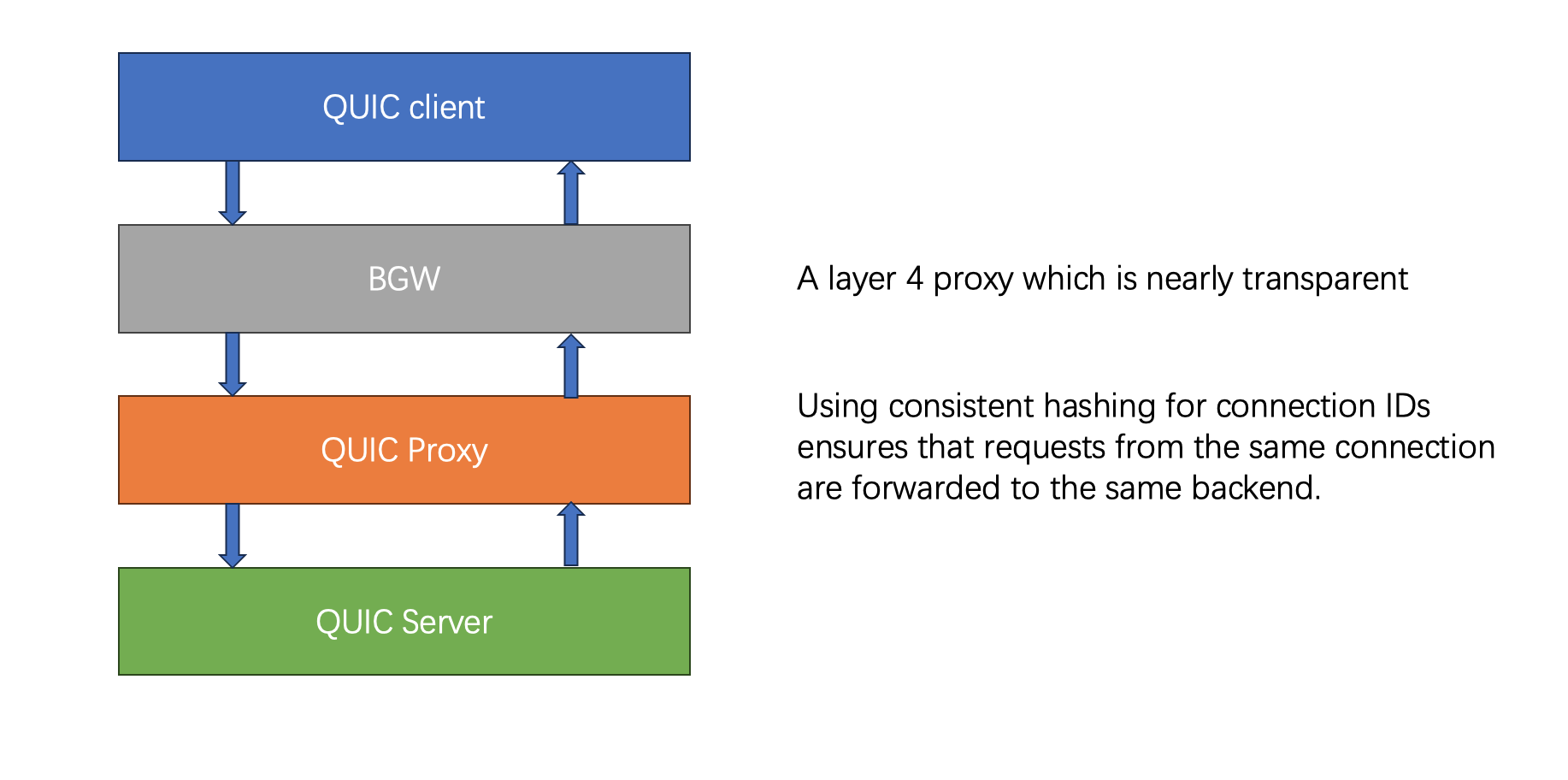
The architecture, shown above, is fairly simple. The problem appeared only once the number of live QUIC connections crossed a certain threshold — roughly 150,000 — and stayed there for a while. At that point we saw sporadic packet loss, which QUIC’s retransmission mechanism then amplified into a cascade: lost packets triggered retransmissions, retransmissions added load, and the added load caused still more loss.
During this project, QUIC was still a draft protocol, and we had made our own modifications to it. For example, because QUIC handshake packets are large and our business server had to deliver certificates during the handshake, we experimented with offloading the first phase of the handshake and certificate delivery to the BGW. That introduced its own problems (sequence-number handling, among others). Those details aren’t relevant here, and in hindsight such changes made smooth operation harder than it needed to be.
Proxy server. The Connection ID is what makes Connection Migration possible: the same connection can be recognized even after the client’s IP and port change. With multiple backend servers, migration only works if the proxy consistently forwards every packet carrying a given Connection ID to the same backend, regardless of the client’s source address. Our proxy — written in C++ with
epoll, running single-threaded — did exactly that, using consistent hashing over the Connection ID to pick the target machine for each UDP packet.
Detecting the Problem
At low connection counts, everything was stable. Under stress, with a high connection count, connections began dropping after a while — almost always due to timeouts. To find out where the drops were happening, I worked through the following.
Packet-Loss Investigation
- Monitor the key metrics.
- Watched CPU, memory, disk I/O, and network I/O at every stage.
- None of these hit a bottleneck, but network I/O spiked exactly when connections started dropping and settled once only a few connections remained.
- Tentative conclusion: network-level packet loss plus QUIC retransmissions.
- Capture packets with
tcpdump.- Feasible with few connections and low traffic.
- With more than 100,000 long-lived connections, the data rate made capture-and-analyze impractical, so I set this approach aside.
- Eliminate intermediate hops.
- The BGW (core company infrastructure) was an unlikely culprit, but I couldn’t rule it out outright.
- So I set up two paths to compare:
- QUIC client → QUIC server
- QUIC client → QUIC proxy → QUIC server
- The first path was clean; the second showed the problem. That pointed at the proxy.
- Possible failure points narrowed to:
- The client failed to send, and packets were lost in transit.
- The client sent, but the proxy never received them.
- The proxy received but didn’t forward.
- The proxy forwarded, but the server never received.
- Sample and analyze logs.
- To localize the bad hop, I added logging along the whole path.
- Logging every connection saturated disk I/O, so I sampled — logging only connections where
Connection ID % 10000 == 1. - The logs showed the client was sending but the proxy was not receiving.
- That left two candidates:
- Packets lost in transit between client and proxy.
- Packets lost during reception on the proxy host — the area I focused on next.
- Re-read the monitoring data.
- A detail I’d glossed over: on the proxy host, network IN was significantly higher than network OUT.
- In other words, packets were arriving at the proxy’s machine, but the proxy process wasn’t getting them — which moved the problem off the wire and onto the host’s receive path.
Pinpointing the Cause
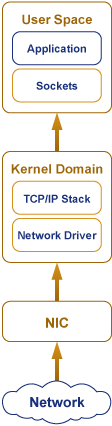
If the bytes reach the NIC but not the application, the loss is happening somewhere in the kernel’s receive path. It helps to have that path in mind explicitly — the same receive path the figure below traces:
NIC (ring buffer) -> softirq / protocol stack -> socket receive buffer -> recvfrom() in the appA UDP datagram can be dropped at any of these handoffs, and Linux exposes a different counter for each. The trick is to read the counters in path order and find the first one that’s incrementing:
- NIC-level drops.
- Command:
ethtool -S <iface>/ifconfig. - Result: no drops at the NIC. The ring buffer and driver were keeping up, so the loss was higher in the stack.
- Command:
- UDP-layer drops.
- Command:
netstat -su(or read/proc/net/snmpdirectly). - Result:
InErrors(packet receive errors) were climbing at ~10k/s, andRcvbufErrorswere climbing too — butInErrorswas growing noticeably faster thanRcvbufErrors. - Reading this correctly matters, and the asymmetry is itself a clue.
RcvbufErrorsincrements specifically when a datagram arrives and there is no room for it in the socket’s receive buffer — in__udp_enqueue_schedule_skb()the kernel drops the packet whensk_rmem_alloc + skb->truesize > sk_rcvbuf(note it’s the skb’s truesize, not its payload, that counts), returns-ENOMEM, and bumpsRcvbufErrors. SoRcvbufErrorsis the counter that uniquely fingerprints socket-buffer overflow from a slow consumer, and its steady climb here was the signal I cared about. InErrorsis the broader bucket, and crucially it’s a superset: on a buffer-full drop the kernel charges the packet toRcvbufErrorsandInErrorstogether, 1:1 (the source even comments that such an error is “charged twice”), soInErrorsis always ≥RcvbufErrors.InErrorsalso books the drops that never touch the socket buffer at all — checksum or length errors, filter/encap drops, a datagram landing on a port with no bound socket. ThatInErrorsclimbed faster therefore just means a fraction of the drops had a cause beyond buffer overflow; theRcvbufErrorsgrowth on its own already points at the diagnosis: an application that isn’t draining its socket fast enough — the kernel has the data but nowhere to put it.
- Command:
- Socket buffer size.
- The proxy already requested a 2 MB receive buffer via
setsockopt(SO_RCVBUF), and the per-socket cap (net.core.rmem_max) was high enough to honor it —SO_RCVBUFis silently clamped tormem_max, so a 2 MB socket buffer means the cap was at least that. (Note:net.core.rmem_defaultis only the default for sockets that never callsetsockopt;net.ipv4.udp_memis a system-wide page-count budget across all UDP sockets, not a per-socket limit. The per-socket ceiling that mattered here isrmem_max.) - So I pushed both up hard —
net.core.rmem_maxand the socket’sSO_RCVBUFto 25 MB — andRcvbufErrorskept growing. - This is the part worth dwelling on, because it’s the most common dead end in packet-loss debugging. A bigger buffer absorbs a burst; it cannot fix a sustained rate mismatch. If datagrams arrive faster than the application drains them, the queue is unstable: utilization ρ = λ/μ ≥ 1, so by the basic queueing stability condition there is no steady state — the backlog grows without bound and any finite buffer eventually fills. (This is precisely the regime where Little’s Law does not apply: L = λW is a steady-state identity for a stable queue; it characterizes the finite backlog you get when consumption keeps up, not the divergence when it doesn’t.) At the ~10k dropped packets/s we were seeing, with ~1.4 KB datagrams, the extra ~25 MB of buffer is only about 25 MB ÷ (10k/s × 1.4 KB) ≈ 1.8 s of surplus — a 25 MB buffer just takes a couple of seconds longer to overflow than a 2 MB one. The buffer was never the cause; it was the symptom. The cause had to be consumption rate.
- The proxy already requested a 2 MB receive buffer via
- Firewall / connection tracking.
- The firewall was disabled, so it wasn’t the cause — but
conntracktable exhaustion is a classic UDP-drop culprit, so I ruled it out anyway:nf_conntrack_countwas far belownf_conntrack_max, with nonf_conntrack: table full, dropping packetin the logs. Those drops would show up in netfilter’s own counters in any case, not as theRcvbufErrorswe were tracking here.
- The firewall was disabled, so it wasn’t the cause — but
- Application load.
- CPU, memory, and disk I/O were all low — which, given everything above, was itself the clue: the process couldn’t be CPU-bound and still be the bottleneck unless it was structurally serialized.
- Application processing model.
- The proxy used a single-threaded, synchronous loop: receive a packet, forward it, repeat.
- A single thread that does one thing at a time can only drain the socket as fast as it can forward — and that ceiling, not the buffer, is what set the drop rate.
At this point the picture was clear: the proxy’s processing capacity was the limit. Re-reading the code confirmed a single-threaded
epollloop that received and synchronously forwarded each packet. Adding per-packet timing showed each packet took roughly 20–50 µs to handle. That caps one thread at 20,000–50,000 packets/second. Beyond that arrival rate, packets pile up in the socket buffer, it overflows, and the kernel drops the excess — exactly theRcvbufErrorswe were seeing.
This also explains every earlier observation at once: network IN > OUT (packets arrive but aren’t forwarded), low CPU (one thread can’t saturate the host), and loss that scales with connection count: under load these are active connections exchanging data (and ACKs), so more connections means a higher aggregate packet rate — exactly the network I/O that spiked with the connection count earlier — pushing further past the single-thread ceiling.
Verification
The proper fix is to refactor the proxy to a multi-threaded, asynchronous design, which raises throughput substantially — but that’s a large change. To validate the hypothesis quickly, I instead ran multiple proxy processes, each listening on its own port, to spread the packet rate across more than one CPU core. With the load divided, the QUIC server held hundreds of thousands of connections reliably. That confirmed the diagnosis: the bottleneck was the single-threaded consumption rate, nothing else.
Retrospective: What I’d Do Differently Today
The multi-process / multi-port trick was the right call for validation — fast, low-risk, and it isolated the variable. But it has a real flaw: spreading connections across multiple ports breaks Connection-ID affinity under migration. Something upstream must now decide which port each datagram lands on. A layer-4 load balancer can only steer by the 4-tuple — but migration changes the 4-tuple (new client IP/port), so after a migration the same Connection ID’s packets hash to a different port, hit a different proxy process, and lose the consistent-hash target. The only way to keep affinity would be for the upstream to route by Connection ID itself — at which point it is solving the exact problem the proxy existed to solve, and the proxy’s hashing is redundant. If I were building this for production now, I’d reach for a few well-established techniques instead:
SO_REUSEPORTover multiple ports. Multiple sockets bound to the same port, with the kernel load-balancing incoming datagrams across them by 4-tuple hash. You get N independent receive queues and N draining threads without changing the port the clients talk to — so the Connection-ID hashing stays intact. (For migration correctness you still want the steering to key on Connection ID.SO_REUSEPORT’s default hash is over the 4-tuple, so it re-buckets a connection the instant the client migrates to a new IP/port — precisely the event Connection IDs exist to absorb — landing the migrated flow on a different socket than its earlier packets.eBPFviaSO_ATTACH_REUSEPORT_EBPFlets you supply a steering program that keys on Connection ID instead, so all of a connection’s packets stay on one socket across migration.)recvmmsg()/sendmmsg(). Batch many datagrams per syscall.recvmmsg()collapses N receive syscalls into one, amortizing the user/kernel transition over a whole batch of, say, 64 datagrams — and on this hot path that transition was a real fraction of the 20–50 µs budget. It won’t touch the rest of that budget, though: the syscall entry/exit is only a few microseconds, and the bulk of the 20–50 µs is work that batching can’t amortize — the per-packet softirq/protocol-stack processing the kernel does regardless, the consistent-hash lookup, and the forwarding send. The kernel still copies each datagram individually and a single socket still serializes the stack work, so the realistic gain is bounded by the fixed syscall share — published numbers for batched UDP receive land closer to tens of percent than to an order of magnitude.sendmmsg()can likewise coalesce the forward sends (each message carries its own destination, so fan-out to different backends is fine), but the routing decision itself stays strictly per-packet and serial.- Decouple receive from forward. Even single-threaded, the synchronous “receive → forward → receive” loop stalls the RX path on every send. A dedicated RX thread that only drains the socket into a lock-free queue, with separate worker threads forwarding, removes that stall and lets the RX side keep up with the kernel — but it isn’t a free pass: it only keeps the socket buffer empty if the workers’ aggregate forward throughput meets or beats the arrival rate. If they can’t, the same stability trap applies one level up — the backlog just migrates from the kernel socket buffer into the userspace queue, which is also finite and will overflow (or you’ll bound it and drop) in its place. Decoupling buys you head-of-line-free draining and lets you scale forwarding independently; it doesn’t manufacture service capacity.
- Push the work down the stack. With NIC multi-queue + RSS the hardware spreads packets across queues and CPUs by a 4-tuple hash before the stack even runs;
RPSdoes the same steering in software (the kernel calls it “a software implementation of RSS”), andRFSgoes one step further, steering each flow to the CPU where its consuming thread actually runs. For the extreme end you drop below the socket layer entirely:XDPruns an eBPF program in the driver’s RX path — before ansk_buffis even allocated — so it can forward a packet (XDP_TXback out the same NIC, orXDP_REDIRECTto another) without ever touching the socket layer, which suits stateless redirect but not a proxy whose Connection-ID hashing lives in userspace.AF_XDPis the related userspace fast path: an XDP program redirects frames into a memory-mapped ring delivered to a dedicatedAF_XDPsocket, bypassing the normal kernel network stack while still handing packets to userspace — the natural fit here, since the existing C++ consistent-hashing logic stays in userspace. This pair is the approach high-performance UDP proxies and L4 load balancers take today.
The deeper lesson has aged well, though: when an application receives data but loses it, suspect the consumption rate before the buffer size. Counters read in path order will tell you which handoff is failing; buffer tuning only ever buys you time against a burst, never against a rate you can’t sustain.